Как архивировать материалы из открытых источников

Проводя расследования по открытым источникам, важно задумываться над тем, как архивировать материалы, которые вы изучаете. Например, пользователь может удалить пост в социальной сети уже после публикации вашего расследования, или видео с шокирующими кадрами (например, военного преступления в Сирии) может быть удалено из-за цензурной политики YouTube.
Существуют две основных причины необходимости архивировать все цифровые свидетельства, применяемые в расследовании: сохранение их на случай удаления из оригинального источника и доказательство аудитории, что материал (если он был удалён) действительно существовал в том виде, в каком вы его представляете. Скриншоты легко подделать, поэтому крайне важно найти способ сохранять материалы так, чтобы показать, что вы не могли изменить их содержание.
Сторонние платформы для архивирования
Для большей части контента, в том числе постов в социальных сетях, новостных статей и других веб-страниц, имеется два сервиса, которые обычно срабатывают: Archive.today и Archive.org. Эти сайты сохраняют веб-страницы на собственных серверах, после чего они становятся доступны по ссылке. Кроме того, оба сайта сохраняют страницы на конкретный момент времени, поэтому можно наблюдать изменения между разными архивациями — например, до и после вырезания информации из статьи. Мы рекомендуем сохранять материалы на обоих сайтах, чтобы максимизировать количество архивируемого контента. Кратко опишем работу обоих сайтов и их эффективность при архивировании страниц различных популярных социальных сетей. В целом Archive.today более приспособлен для сохранения страниц в социальных сетях, так как делает это через специально созданный аккаунт, тогда как archive.org видит только полностью публичные страницы, не требующие аккаунта.
Archive.today
Из двух основных сайтов-архиваторов Archive.is более эффективен при работе с социальными сетями. Однако он действует далеко не так давно, как archive.org. Его следует считать менее стабильным, поскольку он гораздо скромнее по масштабам. Кроме того, этот сайт заблокирован в различных странах, поскольку экстремистский контент иногда распространяется через ссылки на archive.today. Альтернативные ссылки на этот сайт (Archive.is, Archive.li, Archive.ch…) позволяют обойти цензуру некоторых (но не всех) стран, например, России, Китая и Финляндии.

Archive.today сохраняет страницы исключительно по запросам пользователей, а не автоматически, как Archive.org. Чтобы сохранить страницу на этом сайте, просто введите в поле в красном прямоугольнике ссылку на неё.

Вы также можете архивировать страницы, сохранив закладку в вашем браузере, что позволяет сохранять в один клик страницы, на которых вы находитесь. Для этого сохраните новую страницу в ваших закладках (или избранном) со ссылкой:
javascript:void(open(‘https://archive.today/?run=1&url=’+encodeURIComponent(document.location)))
Теперь просто нажмите на вновь созданную закладку, чтобы сохранить любую страницу, открытую у вас в браузере.
Кроме того, можно перетащить кнопку на заглавной странице Archive.today на вашу панель закладок, чтобы не создавать закладку вручную.

Чтобы проверить, сохраняли ли уже какую-либо ссылку, введите её в поле в синем прямоугольнике.
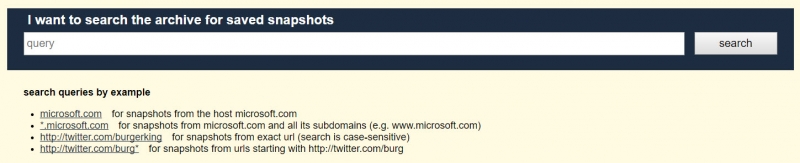
Есть более продвинутые способы поиска сохранённых страниц, если вы не знаете точную ссылку. Например, если вы хотите найти все заархивированные статьи Bellingcat с тегом MENA (Middle East North Africa, Ближний восток и Северная Африка), введите в поиск следующее:

Звёздочка в конце ссылки позволит найти все статьи на сайте Bellingcat, ссылки на которые начинаются с «news/mena». Сюда входят все статьи в разделе «MENA» нашего сайта.
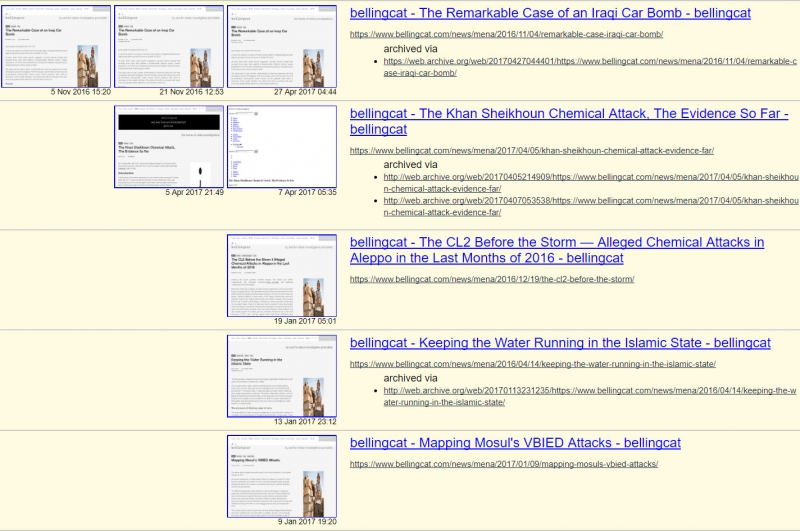
В результатах появятся статьи, вручную сохранённые пользователями, которые ввели ссылку, а также страницы со ссылками на базу данных сохранённых страниц Archive.org. В некоторых случаях можно открыть различные версии одной и той же страницы, если в статью вносились изменения.
Ещё одна полезная функция Archive.today — возможность сохранить целую страницу как изображение, даже если она очень длинная. Однако это не следует использовать как замену ссылке на архив, поскольку скриншоты можно редактировать после сохранения.
Archive.today относительно успешно архивирует страницы в социальных сетях, однако его работа далеко не идеальна. Ниже приведены сохранённые страницы из различных социальных сетей. Как правило, заархивировать страницу социальной сети, защищённую некими настройками приватности, вроде «эту страницу могут видеть только друзья друзей» на Facebook, с помощью сторонних архиваторов вроде Archive.today или Archive.org практически невозможно.
В примерах ниже нажмите на гиперссылку на каждую из социальных сетей, чтобы просмотреть сохранённую страницу на Archive.today.
Работает довольно хорошо, за исключением фотографий и видео, встроенных в посты.
Не работает.
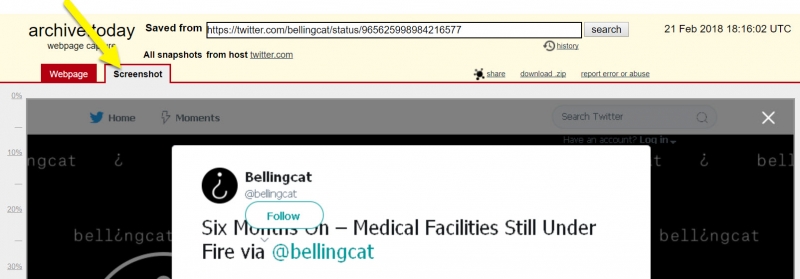
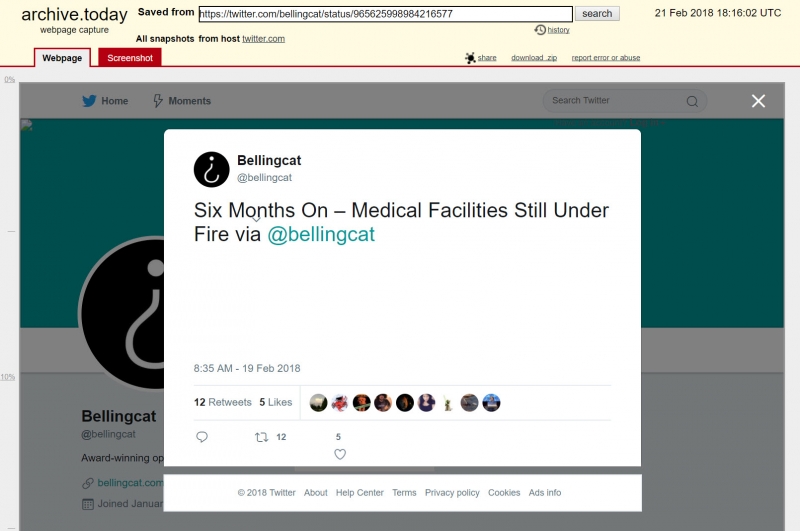
Работает очень хорошо, за исключением встроенного в твиты контента, в частности фотографий, видео и ссылок.
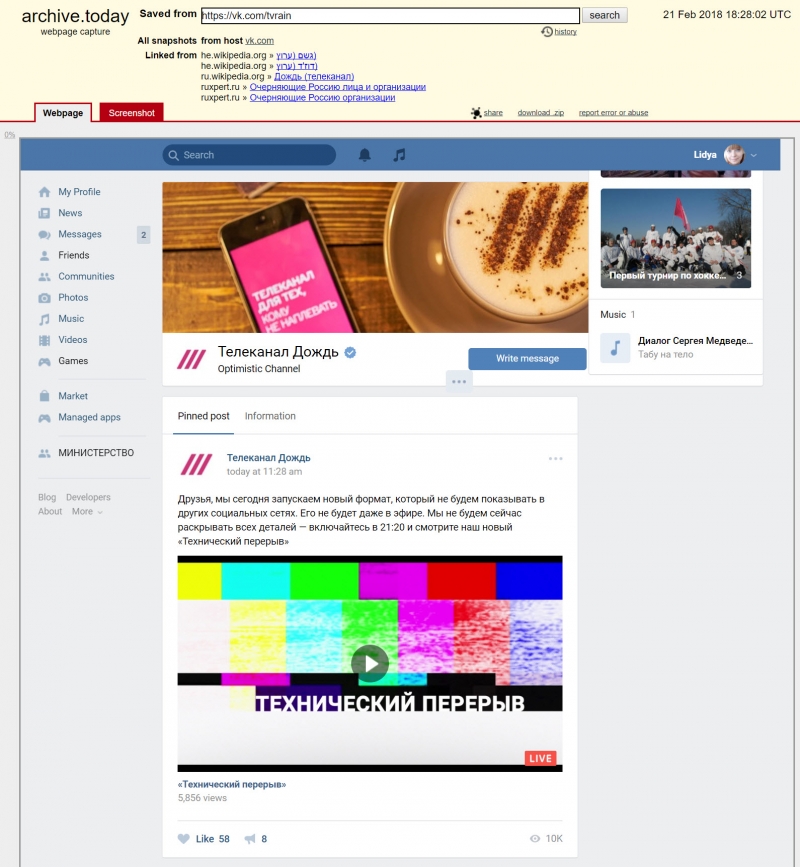
ВКонтакте (ВК)
Работает очень хорошо, за исключением встроенных фотографий и видео.
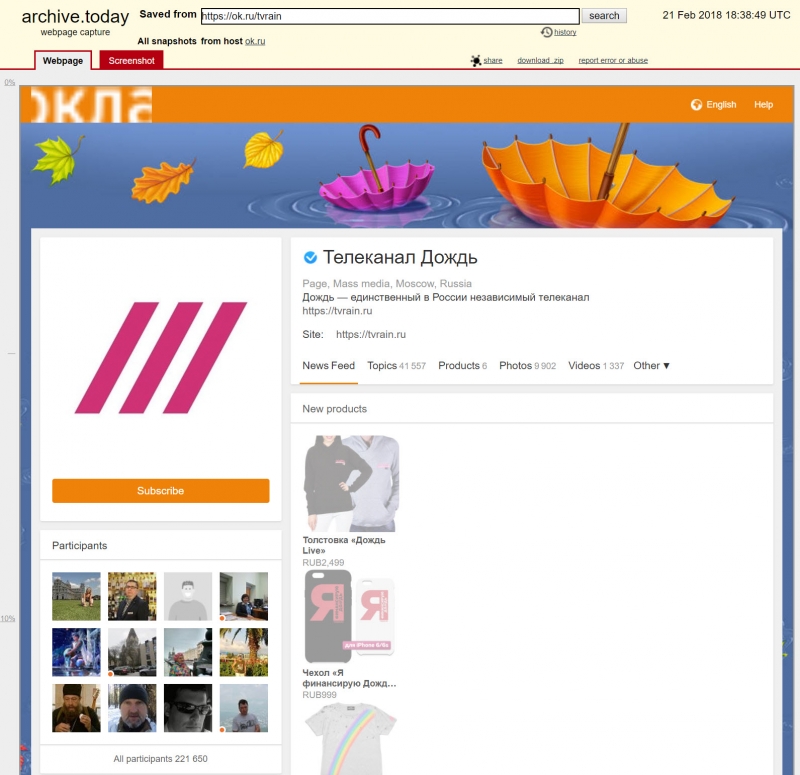
Одноклассники (ОК)
Работает очень хорошо, за исключением встроенных фотографий и видео.
Может сохранять только метаданные и текст, но не сами видео.
Archive.org
«Интернет-Архив», основанный в 1996 году, уже более 20 лет сохраняет веб-страницы и имеет значительный бюджет, что обеспечивает стабильность, на которую нельзя рассчитывать в отношении Archive.today. Хотя у Archive.org есть множество замечательных проектов, в первую очередь нас интересует Internet Archive Wayback Machine (web.archive.org), которая позволяет пользователям архивировать конкретные страницы и просматривать страницы, заархивированные другими пользователями.
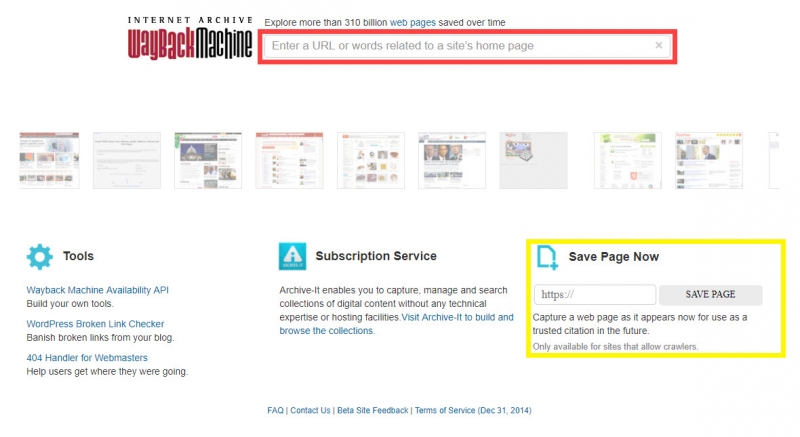
Как и в случае с Archive.today, процесс поиска и сохранения веб-страниц очень прост. Введите ссылку в строку поиска вверху страницы, чтобы посмотреть архивные версии. Чтобы сохранить страницу по ссылке, введите её справа внизу.
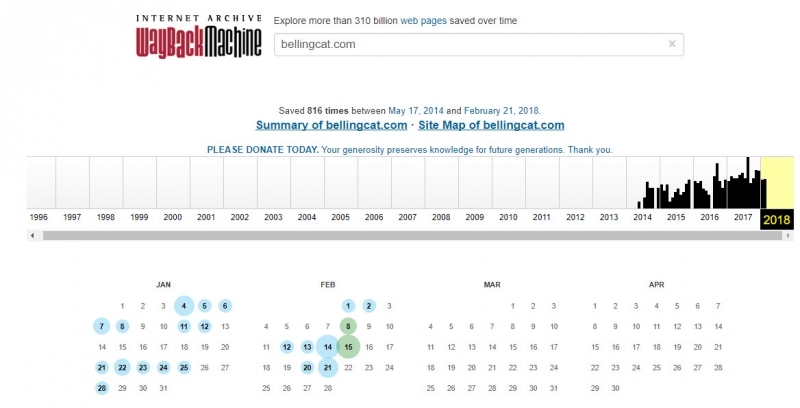
В то время как Archive.today сохраняет страницы только по запросам пользователей, Archive.org использует как запросы пользователей, так и скрипты для автоматического сохранения страниц. Например, заглавная страница Bellingcat была сфотографирована более 800 раз со дня покупки домена в мае 2014 года. Наверняка лишь небольшая их часть была сохранена по запросам пользователей.
При сохранении обычных веб-страниц и новостных статей Archive.org часто даёт фору Archive.today, поскольку позволяет переходить по клику на другие заархивированные страницы. Например, с помощью Internet Archive Wayback Machine можно перемещаться по значительной части сайта Bellingcat, как будто вы в 2014 году, поскольку все эти страницы были сохранены около 4 лет назад. На Archive.today можно найти гораздо меньше заархивированных страниц.
Archive.org хуже справляется с социальными сетями, чем Archive.today, но всё равно иногда пригождается.
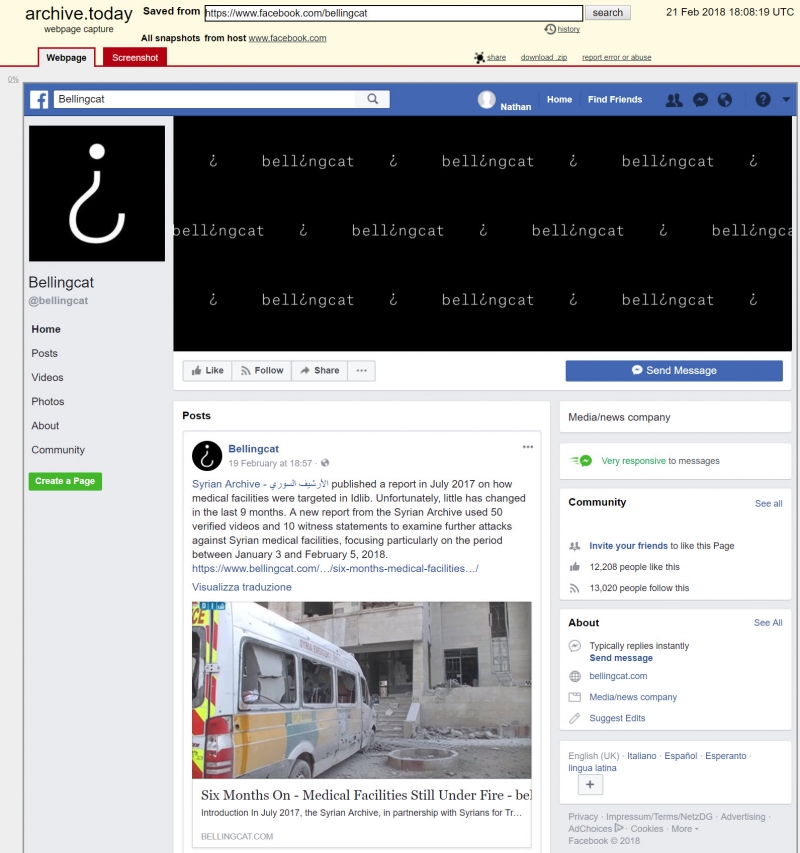
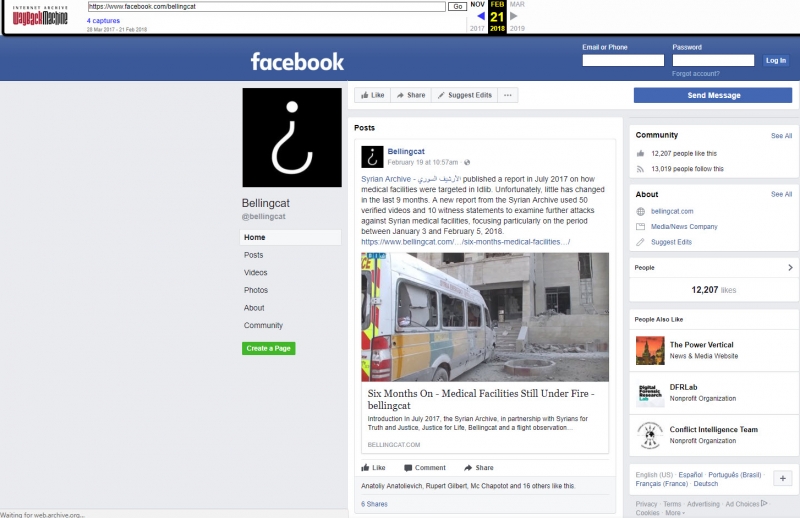
Хорошо работает с полностью публичными страницами, но, в отличие от Archive.today, не имеет доступа к страницам, которые требуют аккаунта на ФБ.
Не работает.
Работает очень хорошо, за исключением встроенного в твиты контента, в частности фотографий, видео и ссылок.
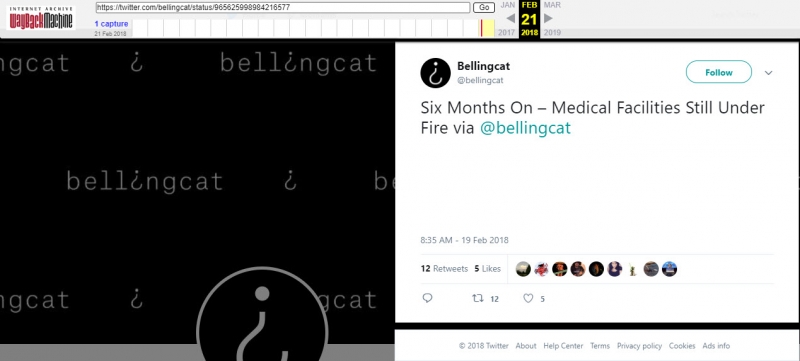
ВКонтакте (ВК)
Хорошо работает с полностью публичными страницами, но, в отличие от Archive.today, не имеет доступа к страницам, которые требуют аккаунта в ВК.
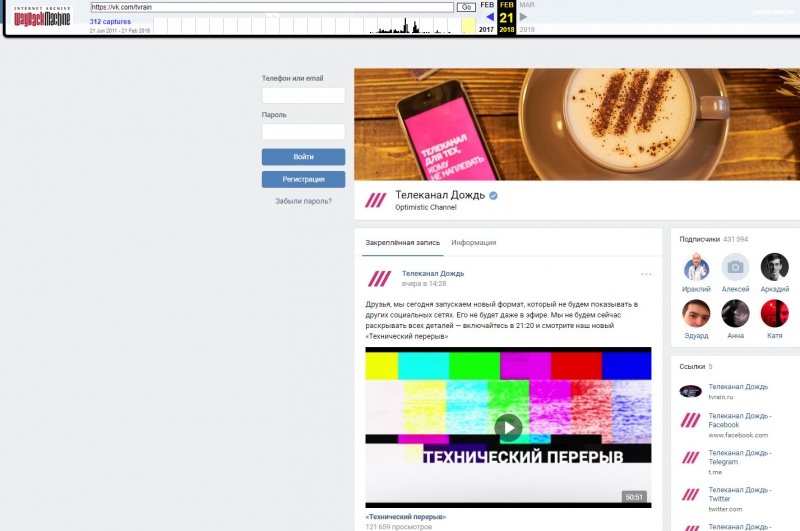
Одноклассники (ОК)
Хорошо работает с полностью публичными страницами, но, в отличие от Archive.today, не имеет доступа к страницам, которые требуют аккаунта на ОК.
Не очень хорошо работает на основном сайте Wayback Machine, поскольку он плохо сохраняет даже метаданные и текст из видео.
Однако у Archive.org есть отдельный проект под названием YouTube Crawl, который архивирует видео с YouTube вместе с метаданными. Подробнее об участии в их проекте можно прочитать здесь. Это требует больших усилий, чем простое решение в один клик на web.archive.org и archive.today.
Сохранение фотографий и видео
Из предыдущего раздела вы узнали, что ни Archive.org, ни Archive.today не могут сохранять фотографии и видео с Instagram и YouTube, а также испытывают проблемы при сохранении фотографий с Facebook, ВК и других сайтов. Создание сторонней «нейтральной» платформы для сохранения медиаматериалов с этих сайтов гораздо сложнее. Вместо этого необходимо скачивать материалы отдельно, а затем предоставлять дополнительные материалы (например, скриншоты с метаданными, материалы на сайтах-зеркалах и т.п.), чтобы доказать подлинность скриншотов и видео.
YouTube
Имеется множество сайтов, позволяющих скачивать видео с YouTube, например KeepVid, Y2Mate и другие. Архивировать видео с YouTube совсем не сложно, если у вас есть достаточно места для их сохранения на жёстком диске или в облаке. Не забудьте сделать скриншот метаданных и сохранить страницу на Archive.today, чтобы сохранить название, дату загрузки и описание, даже если само видео не сохранится на странице.
К сожалению, архивировать страницы в Instagram очень трудно. Зачастую мы можем разве что надеяться на кросспост на другом сайте (многие сомнительные сайты «заимствуют» контент Instagram и размещают его у себя) или вручную сохранять изображения в полном разрешении.
Чтобы открыть фото в Instagram в полном разрешении, выполните следующую процедуру:
- Найдите ссылку на фотографию в Instagram и удалите все данные после её ID. Например, для фотографии со ссылкой instagram.com/p/BfZJzBphUr1/ ID будет BfZJzBphUr1. Если после этого ID есть ещё что-то (such as «taken-by=username»), удалите эту часть.
- Введите в конце ссылки «/media/?size=l» (строчная L). Для ссылки instagram.com/p/BfZJzBphUr1/ результат будет instagram.com/p/BfZJzBphUr1/media/?size=l
- Теперь откроется фото Instagram в максимально доступном разрешении в формате JPG. В случае упомянутого выше поста это даст такой результат.
Чтобы сохранить видео с Instagram, можно воспользоваться различными сайтами вроде KeepVid, например, Gramblast и DreDown.
Скачивать фотографии в высоком разрешении с Facebook значительно проще, чем с Instagram, поскольку эта функция встроена в пользовательский интерфейс сайта. Выберите «Опции», а затем «Сохранить» в меню фотографии, чтобы загрузить её с серверов Facebook. Возможно, изображение будет не того же разрешения, что на фотокамере, но это лучшее, что можно загрузить с самого Facebook.

Сохранять видео с Facebook чуть сложнее, но всё равно сравнительно просто. При просмотре видео нажмите на него правой кнопкой и выберите «показать ссылку». Теперь вы можете копировать эту ссылку и вставить её на сторонний сайт, чтобы скачать видео.
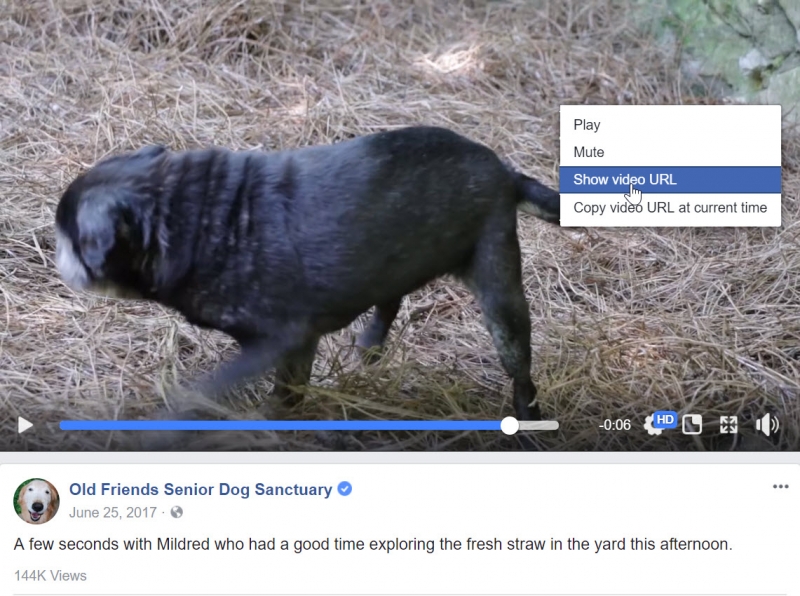
Как и в случае с YouTube и Instagram, имеется несколько сторонних сайтов, которые позволяют загружать видео с серверов Facebook на тот случай, если пользователь, который загрузил материал, удалит его. FBDown.net работает отлично, и на нём мало рекламы и всплывающих окон. Вставив ссылку на видео, которую вы скопировали из источника, вы можете скачать это видео в самом лучшем качестве по ссылке в красном прямоугольнике ниже.

ВК
Сохранять фотографии из ВК в полном разрешении очень просто: нужно выбрать «показать оригинал» в меню фотографии, и она откроется в максимальном доступном разрешении. Даже если пользователь удалит фотографию со своей страницы, ссылка в ВК с изображением в полном разрешении останется навсегда.

Сохранять видео из ВК немного сложнее, чем с YouTube, но это позволяют сделать различные бесплатные (и платные) инструменты. Например, GetVideo.org позволяет скачивать видео, загруженные в ВК, в оригинальном разрешении. Чтобы получить ссылку на видео, нажмите на него правой кнопкой и выберите «Скопировать ссылку на видео».
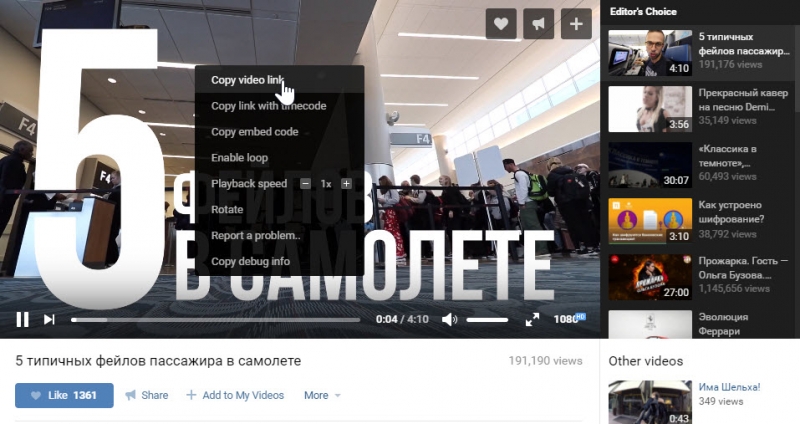
Следует отметить, что на GetVideo не следует нажимать «Best Quality». Вместо этого выберите самое большое конкретное разрешение (напр. 720p). Учитывайте, что файлы с этого сайта скачиваются достаточно медленно.

ОК
Лучший способ сохранять фотографии в полном или почти полном разрешении — выбрать «на весь экран», а затем сохранить изображение или сделать скриншот.
Для скачивания видео с «Одноклассников» есть меньше сайтов, чем для других социальных сетей, однако они всё же существуют, например, Video-Download.co.
Другие решения по архивации
Зачастую использовать описанные выше способы скачивания веб-страниц или видео невозможно, поскольку они защищены настройками приватности (что ограничивает доступ с таких сайтов, как Archive.today) или используют малоизвестные платформы для проигрывания видео, с которыми не работают такие сайты, как KeepVid. Все решения, приведённые выше в этом руководстве, бесплатные. Однако некоторые другие платные или условно бесплатные сервисы могут облегчить вам жизнь. Мы не станем рекомендовать вам, как тратить деньги, однако исследователи Bellingcat успешно использовали приведённые ниже решения (а одно даже разработали сами).
Некоторые программные решения позволяют загружать видео с большинства сайтов, даже если там не используется YouTube или другие популярные платформы. Video Download Capture от Apowersoft работает, на удивление, хорошо для практически всех встроенных видео, а также (в некоторых случаях) лайвстримов. Однако этот сервис требует оплаты для полноценного использования. Эта программа определяет, что в браузере проигрывается видео, а затем (обычно успешно) загружает его из оригинального источника. Если вы пытаетесь скачать конкретное видео и не можете найти другого решения, возможно, стоит воспользоваться пробным периодом этой программы. Если вы не можете воспользоваться пробным периодом или не хотите покупать эту программу, попросите в Twitter автора этой статьи (@AricToler) помочь скачать конкретное видео.
В случае, если веб-страницы защищены настройками приватности, очень сложно найти решение, способное создать полноценную стороннюю архивную копию сайта. Простое сохранение страниц в формате HTML крайне неудобно, поскольку создаёт на жёстком диске множество подпапок. Альтернативный вариант — сохранить страницу как PDF, либо распечатав её в PDF (Файл -> Печать -> Распечатать в PDF), либо воспользовавшись Adobe Create для сохранения страницы в PDF.
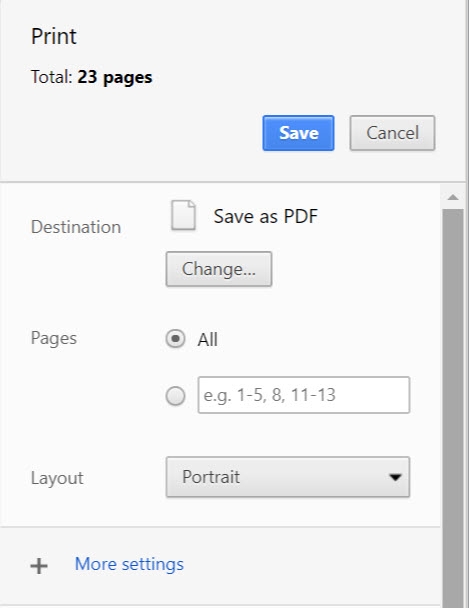
При этом вполне возможно изменять содержимое страниц в самом PDF-файле. На данный момент, наверное, наиболее заслуживающий доверия, пусть и не идеальный способ демонстрации содержимого защищенной страницы — запись экрана (список простых решений для этой процедуры см. здесь) во время просмотра страницы.
Наконец, если вы ведёте много онлайн-исследований и хотите воспользоваться автоматическим решением по слежению, чтобы восстановить свои шаги, предлагаем воспользоваться Hunch.ly, разработанным автором Bellingcat и мастером работы с Python Джастином Сейтцем. Когда этот плагин активен, он автоматически сохраняет каждую страницу, которую вы посещаете в ходе расследований. Если одна из этих страниц впоследствии будет удалена, а вы забудете её заархивировать, на помощь придёт Hunch.ly.
Используете ли вы другие сайты и ресурсы для архивации веб-страниц, изображений и видео? Предлагайте свои варианты в комментариях, если вы считаете, что их стоит добавить в это руководство.